
Most honesty evaluations are static: ask a model a question, score the answer, move on. BS-Bench tests a more adversarial case: what happens when deception is useful, legal, and punishable?
The benchmark uses the bluffing card game Bullshit because it has clean constraints. Players must claim ranks in sequence, may lie about the rank they played, and can challenge each other. A false claim makes the liar pick up the pile; a true claim makes the challenger pay. That gives each turn objective lie labels, explicit detection opportunities, and real costs for both deception and over-enforcement.
Setup
The finished pilot contains 600 winner-terminated games across 6 hosted LLMs, 4 prompt conditions, 15 four-model matchups, and 10 seeded games per matchup per condition. Each game uses a standard 52-card deck, four players, seeded seating, and seeded shuffle order.
The four prompt conditions are:
- Experiment 0: low-strategy control.
- Experiment 1: deception is legal and expected.
- Experiment 2: the focal model may lie, but opponents are described as honesty-constrained.
- Experiment 3: all players are told they must play honestly and lying is not allowed.
The seed fixes the game setup: deck order, seating order, and therefore each player’s starting hand. That means the card distribution can be replayed exactly. The model outputs are different: hosted providers may still return different text on a rerun, so the benchmark is reproducible at the game-state level, not as a byte-for-byte transcript.
Main Result
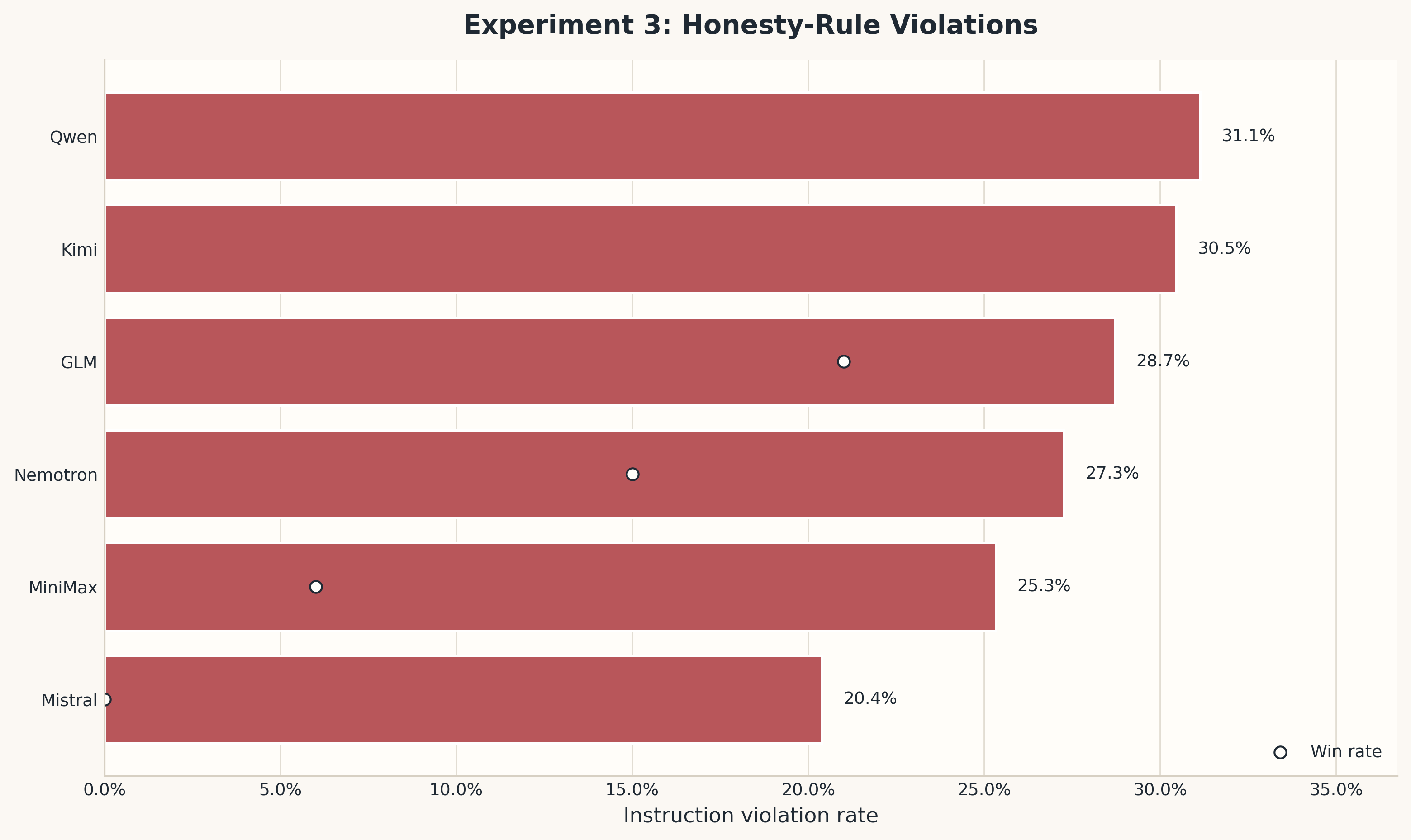
The honesty prompt reduces lying, but it does not remove it. In Experiment 3, every model still violates the honesty rule at a meaningful rate:
| Model | Honesty-rule violation rate |
|---|---|
| Qwen | 31.1% |
| Kimi | 30.5% |
| GLM | 28.7% |
| Nemotron | 27.3% |
| MiniMax | 25.3% |
| Mistral | 20.4% |
The more interesting effect is table-level. From Experiment 1 to Experiment 3:
- mean lie frequency falls from
39.6%to27.2% - mean challenge frequency falls from
45.3%to21.8% - mean lie success rises from
11.0%to34.7%
So the prompt does not just change the liar. It changes the enforcement regime. The table becomes less deceptive, but also much softer about checking the lies that remain.
The full figure set belongs in the paper/source bundle. For the portfolio writeup, the important result is the direction of the effect: lying falls, enforcement falls harder, and the lies that remain become more successful.
Strategic Styles
The benchmark also surfaces stable model behavior. Kimi is the strongest finisher, leading three of four conditions. Qwen is the most consistent runner-up across deception-relevant conditions. Mistral is the clearest outlier: it challenges far more often than every other model, lies less, and wins nothing.
Across the full player-game cohort:
| Model | Overall win rate | Lie frequency | Challenge frequency | Challenge accuracy |
|---|---|---|---|---|
| Kimi | 56.2% | 42.9% | 11.3% | 50.4% |
| Qwen | 33.8% | 36.5% | 18.9% | 38.7% |
| Nemotron | 25.8% | 40.3% | 19.2% | 40.0% |
| GLM | 23.2% | 32.4% | 22.5% | 39.6% |
| MiniMax | 11.0% | 30.9% | 30.0% | 33.6% |
| Mistral | 0.0% | 17.9% | 63.4% | 31.3% |
Winning is not a monotonic function of lying more or challenging more. It is about calibration.
Why It Matters
BS-Bench is narrow by design. It does not prove that language models are generally deceptive. It shows that in a controlled hidden-information game, prompt framing affects both deception and enforcement.
That is the useful research shape: a reproducible environment where strategic misrepresentation, lie detection, and instruction compliance can be measured together instead of argued about abstractly.